二叉樹,顧名思義,每個節點最多有兩個 “叉”,也就是兩個子節點,分別是左子節點和右子節點。不過,二叉樹並不要求每個節點都有兩個子節點,有的節點只有左子節點,有的節點只有右子節點。
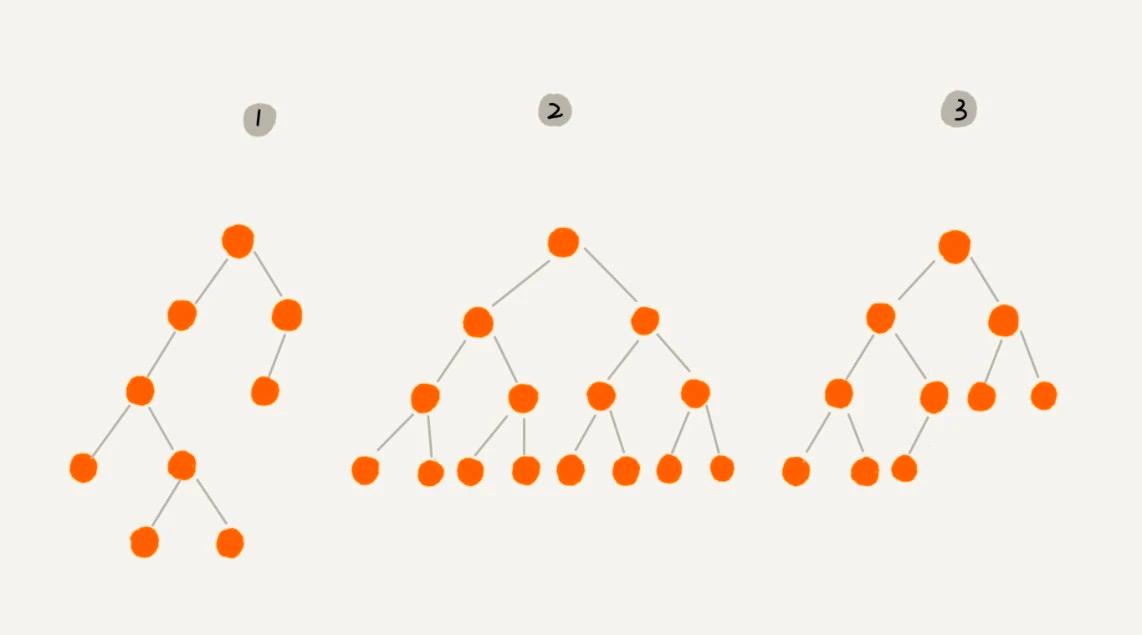
編號 2 的二叉樹中,葉子節點全都在最底層,除了葉子節點之外,每個節點都有左右兩個子節點,這種二叉樹就叫做 滿二叉樹。
編號 3 的二叉樹中,葉子節點都在最底下兩層,最後一層的葉子節點都靠左排列,並且除了最後一層,其他層的節點個數都要達到最大,這種二叉樹叫做 完全二叉樹。
如何表示(或者存儲)一棵二叉樹?#
一種是基於指針或者引用的二叉 鏈式存儲法,一種是基於數組的 順序存儲法。
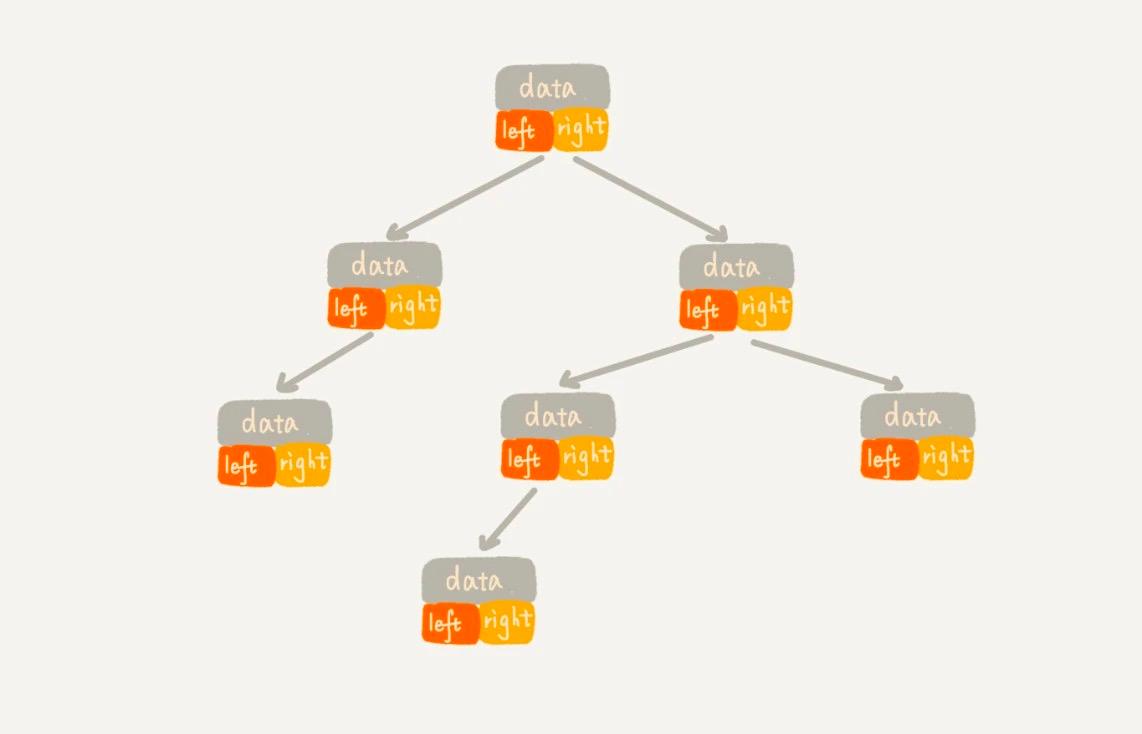
鏈式存儲法。從圖中你應該可以很清楚地看到,每個節點有三個字段,其中一個存儲數據,另外兩個是指向左右子節點的指針。我們只要拎住根節點,就可以通過左右子節點的指針,把整棵樹都串起來。這種存儲方式我們比較常用。大部分二叉樹代碼都是通過這種結構來實現的。
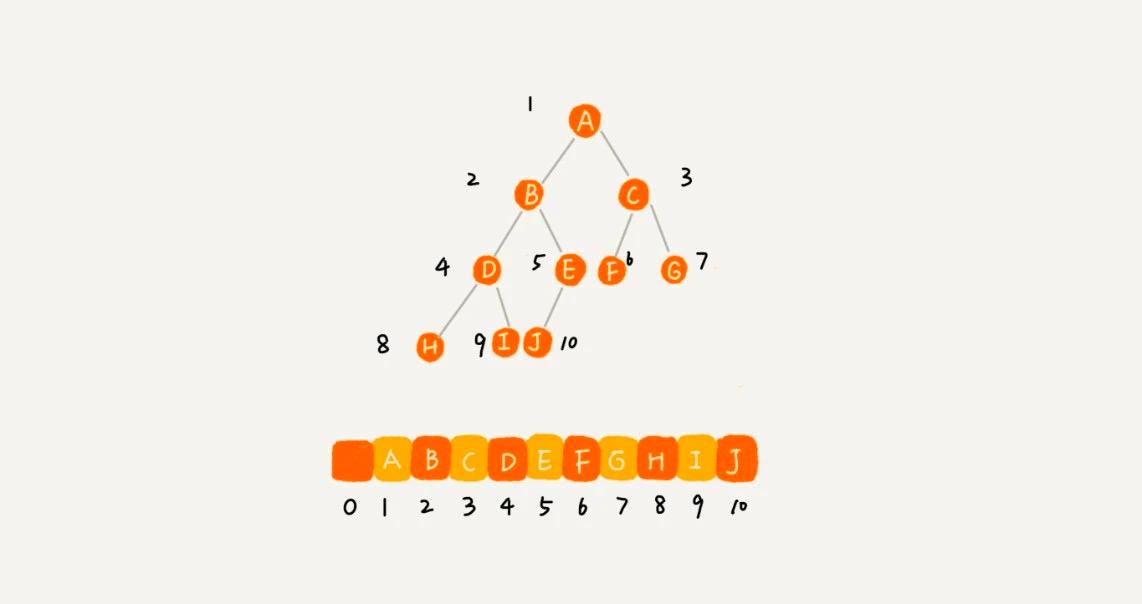
基於數組的順序存儲法。我們把根節點存儲在下標 i = 1 的位置,那左子節點存儲在下標 2 * i = 2 的位置,右子節點存儲在 2 * i + 1 = 3 的位置。以此類推,B 節點的左子節點存儲在 2 * i = 2 * 2 = 4 的位置,右子節點存儲在 2 * i + 1 = 2 * 2 + 1 = 5 的位置。
剛剛舉的例子是一棵完全二叉樹,所以僅僅 “浪費” 了一個下標為 0 的存儲位置。如果是非完全二叉樹,其實會浪費比較多的數組存儲空間。可以看舉的下面這個例子
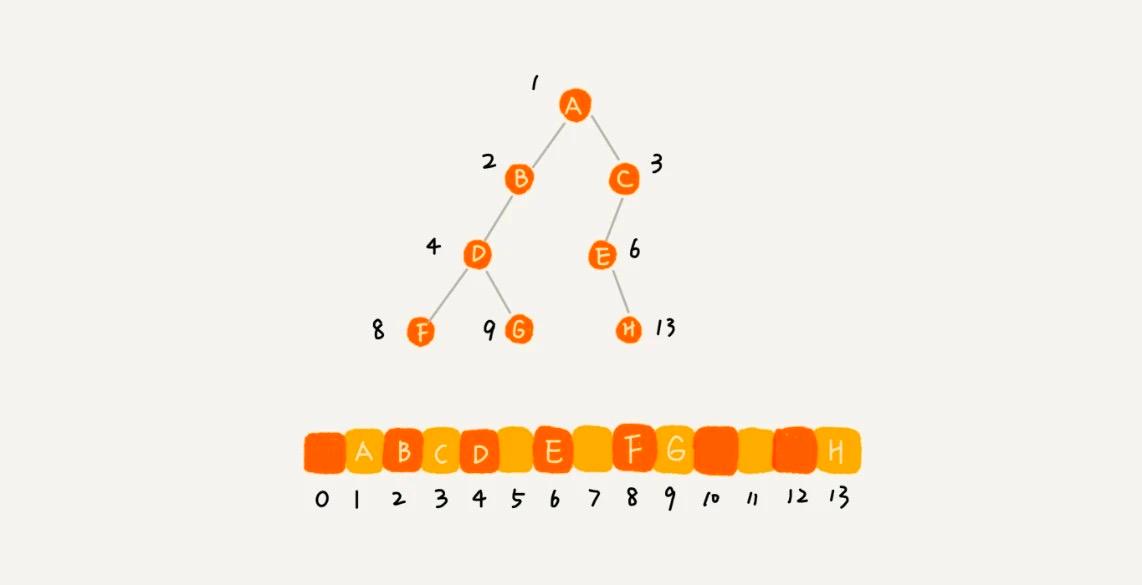
所以,如果某棵二叉樹是一棵完全二叉樹,那用數組存儲無疑是最節省內存的一種方式。因為數組的存儲方式並不需要像鏈式存儲法那樣,要存儲額外的左右子節點的指針。這也是為什麼完全二叉樹會單獨拎出來的原因,也是為什麼完全二叉樹要求最後一層的子節點都靠左的原因。
二叉樹的遍歷#
經典的方法有三種,前序遍歷、中序遍歷和後序遍歷:
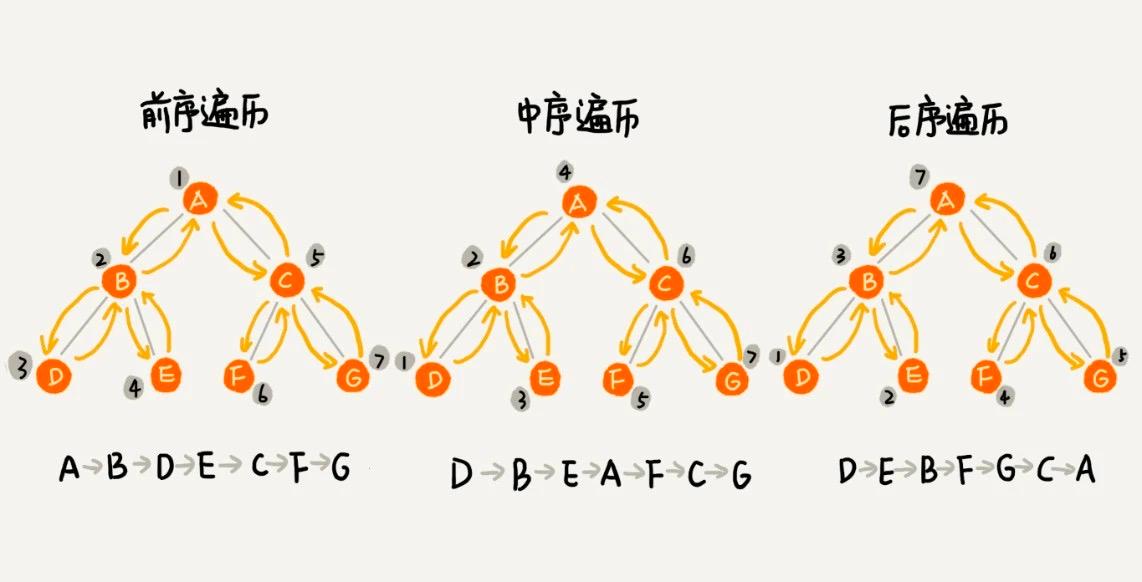
- 前序遍歷:對於樹中的任意節點來說,先打印這個節點,然後再打印它的左子樹,最後打印它的右子樹。
- 中序遍歷:對於樹中的任意節點來說,先打印它的左子樹,然後再打印它本身,最後打印它的右子樹。
- 後序遍歷:對於樹中的任意節點來說,先打印它的左子樹,然後再打印它的右子樹,最後打印這個節點本身。
實際上就是遍歷本身節點的順序問題。
// 先序
function preOrder(root) {
if (root == null) return;
console.log(root.value);
preOrder(root.left);
preOrder(root.right);
}
// 中序
function inOrder(root) {
if (root == null) return;
inOrder(root.left);
console.log(root.value);
inOrder(root.right);
}
// 後序
function postOrder(root) {
if (root == null) return;
postOrder(root.left);
postOrder(root.right);
console.log(root.value);
}
二叉查找樹#
也叫二叉搜索樹,二叉查找樹最大的特點就是,支持動態數據集合的快速插入、刪除、查找操作。
二叉查找樹要求,在樹中的任意一個節點,其左子樹中的每個節點的值,都要小於這個節點的值,而右子樹節點的值都大於這個節點的值。

1. 二叉查找樹的查找操作#
我們先取根節點,如果它等於我們要查找的數據,那就返回。如果要查找的數據比根節點的值小,那就在左子樹中遞歸查找;如果要查找的數據比根節點的值大,那就在右子樹中遞歸查找。

function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
function searchBST(root, val) {
while (root !== null && val !== root.val) {
root = val < root.val ? root.left : root.right;
}
return root;
}
2. 二叉查找樹的插入操作#
如果要插入的數據比節點的數據大,並且節點的右子樹為空,就將新數據直接插到右子節點的位置;如果不為空,就再遞歸遍歷右子樹,查找插入位置。同理,如果要插入的數據比節點數值小,並且節點的左子樹為空,就將新數據插入到左子節點的位置;如果不為空,就再遞歸遍歷左子樹,查找插入位置。

function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
function insertBST(root, val) {
if (root === null) {
root = new TreeNode(val);
return root;
}
while (root != null) {
if (val > root.val) {
if (root.right == null) {
root.right = new TreeNode(val);
return root;
}
root = root.right;
} else {
if (root.left == null) {
root.left = new TreeNode(val);
return root;
}
root = root.left;
}
}
}
3. 二叉查找樹的刪除操作#
針對要刪除節點的子節點個數的不同,我們需要分三種情況來處理。
- 如果要刪除的節點沒有子節點,我們只需要直接將父節點中,指向要刪除節點的指針置為 null。比如圖中的刪除節點 55。
- 如果要刪除的節點只有一個子節點(只有左子節點或者右子節點),我們只需要更新父節點中,指向要刪除節點的指針,讓它指向要刪除節點的子節點就可以了。比如圖中的刪除節點 13。
- 如果要刪除的節點有兩個子節點,這就比較複雜了。我們需要找到這個節點的右子樹中的最小節點,把它替換到要刪除的節點上。然後再刪掉這個最小節點,因為最小節點肯定沒有左子節點(如果有左子結點,那就不是最小節點了),所以,我們可以應用上面兩條規則來刪除這個最小節點。比如圖中的刪除節點 18。

function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
function deleteNode(root, key) {
if (!root) return null;
if (root.val > key) {
root.left = deleteNode(root.left, key);
return root;
}
if (root.val < key) {
root.right = deleteNode(root.right, key);
return root;
}
if (root.val === key) {
if (!root.left && !root.right) {
return null;
}
if (!root.right) {
return root.left;
}
if (!root.left) {
return root.right;
}
let p = root.right;
while (p.left) {
p = p.left;
}
root.right = deleteNode(root.right, p.val);
p.right = root.right;
p.left = root.left;
return p;
}
};
平衡二叉查找樹#
平衡二叉樹:二叉樹中任意一個節點的左右子樹的高度相差不能大於 1。從這個定義來看,完全二叉樹、滿二叉樹其實都是平衡二叉樹,但是非完全二叉樹也有可能是平衡二叉樹。

平衡二叉查找樹不僅滿足上面平衡二叉樹的定義,還滿足二叉查找樹的特點。最先被發明的平衡二叉查找樹是AVL樹,它嚴格符合平衡二叉查找樹的定義,即任何節點的左右子樹高度相差不超過 1,是一種高度平衡的二叉查找樹。
發明平衡二叉查找樹這類數據結構的初衷是,解決普通二叉查找樹在頻繁的插入、刪除等動態更新的情況下,出現時間複雜度退化的問題。
所以,平衡二叉查找樹中 “平衡” 的意思,其實就是讓整棵樹左右看起來比較 “對稱”、比較 “平衡”,不要出現左子樹很高、右子樹很矮的情況。這樣就能讓整棵樹的高度相對來說低一些,相應的插入、刪除、查找等操作的效率高一些。
紅黑樹#
紅黑樹的英文是 “Red-Black Tree”,簡稱 R-B Tree。它是一種不嚴格的平衡二叉查找樹。紅黑樹中的節點,一類被標記為黑色,一類被標記為紅色。除此之外,一棵紅黑樹還需要滿足這樣幾個要求:
- 根節點是黑色的
- 每個葉子節點都是黑色的空節點,也就是說,葉子節點不存儲數據
- 任何相鄰的節點都不能同時為紅色,也就是說,紅色節點是被黑色節點隔開的
- 每個節點,從該節點到達其可達葉子節點的所有路徑,都包含相同數目的黑色節點